Centrino čtvrté generace 1 - Merom
21. 6. 2006 07:00 Rubrika: Technologie Autor: Jakub Pavlis
Přestože Centrino Napa má za sebou sotva půl roku života, začaly pomalu prosakovat informace o nové generaci, pracovně pojmenované Santa Rosa. Oproti všem předchozím generacím má jednu zvláštnost, její vstup na trh je hodně spojován i s novým OS, s Windows Vista. Pojďme si tedy shrnout dostupné informace. Dnes se zaměříme na procesory s jádrem Merom.

Centrino Santa Rosa bude už čtvrtou generací úspěšného „vynálezu“ firmy Intel. Prodej celé sady součástek pod jedním názvem se ukázal být vynikajícím marketingovým tahem. Když nic jiného, nakupující jediným pohledem odhalí Centrino logo a může si být jistý, že dostane kvalitní a odzkoušenou technologii. Navíc Intel přišel i s tím, že sadu modernizuje pravidelně vždy začátkem roku, což umožňuje zákazníkům lépe dlouhodobě plánovat nákup výpočetní techniky. Na Santa Rosu se můžeme těšit pravděpodobně v březnu roku 2007.
Základním faktem o Centrinu, na který nesmíme v žádném případě zapomenout, je to, že se jedná o sadu. Tvořena je třemi základními komponentami – procesorem, čipsetem a Wi-Fi čipem. My se dnes budeme zabývat především procesorem, ke zbývajícím komponentám se vrátíme ve druhém díle tohoto článku.
Příběh značky Core
Přestože Core architektura vlastně ani není na trhu, má za sebou už pohnutý příběh a jeden po sobě pojmenovaný produkt. Ale vraťme se na začátek. Pentia III byla velikým úspěchem, ale když začala zastarávat, stál Intel před otázkou, kterým směrem se ubírat. Nakonec zvítězila strategie brutálního výkonu na vysokých frekvencích a výrobní architektura NetBurst. Přestože šlo o moderní technologii a velký krok vpřed, přinesl s sebou řadu poměrně zásadních problémů. Z hlediska notebooků byla tím nejdůležitějším problémem obrovská energetická náročnost – Pentia 4 měla často spotřebu větší než celý dnešní notebook. A další problémy se hromadily kolem: vysoká výhřevnost, problémy s chlazením, vysoká hlučnost, obtíže s ergonomií (teplota klávesnice ap.) a výdrž na baterie.
Další problémy souvisely s tím, že miniaturizace výrobního procesu nesnižovala dostatečně nároky na spotřebu ani dostatečně nezvyšovala možnosti taktování procesoru. Ale hlavním problémem se nakonec ukázala ještě jiná věc – dlouhé pipelines snižovaly možnosti paralelizace výpočtů. S tou totiž Intel příliš nepočítal a najednou se ukázalo, že to bude ta správná cesta vpřed, a tedy že NetBurst byl jen slepou uličkou.

Už v době desktopové dominance Pentií 4 se ukazovala nutnost vytvořit konkurenceschopný procesor pro mobilní nasazení. A tak vzniknul procesor Pentium M. Vracel se ke staré, ale osvědčené a jednoduché architektuře Pentia III, ale přinesl i dramatické změny a vyšší frekvence. Flexibilita této technologie byla taková, že se začala prosazovat i v desktopové sféře, nabízela dostatečný výkon a tolik možností navíc. V okamžiku, kdy konečně zvítězila myšlenka vícejádrových systémů, byla vytvořena značka Core, která má nahradit stařičké a otřepané Pentium. Impulsem bylo právě použití více jader, ale protože Intel neměl dost času na vývoj a byl pod tlakem konkurenční AMD, pro první generaci Core (Solo i Duo) bylo zvoleno jádro Yonah postavené právě na architektuře Pentia M (které svou filosofií sahá až k prastarému Pentiu Pro).
Přehled vlastností Meromu
Nakolik je tedy nová architektura Core opravdu nová? Nejprve si uvedeme stručné shrnutí toho, co nabízí a s čím se budete setkávat v recenzích či představeních: Dvoujádrový procesor Core 2 Duo je pochopitelně 64bitový procesor, první svého druhu v mobilní sféře, který Intel vyprodukuje. Přidrží se ovšem produkční technologie známé už z Yonahu, takže očekávejme „jen“ 65 nm. Bude podporovat 667 MHz FSB, později se počítá i s 800 MHz. Vyrovnávací mezipaměť L2 bude v rozmezí 2 – 4 MB, jádra budou taktována na 1,83 – 2,33 GHz. Oproti Yonahu (Core Duo) se s výkonem zvedne i spotřeba, počítá se s 34 W u standardních a 9 W u ULV verzí. Procesory Core 2 Duo budou také používat patici 479.

Procesory Core 2 Duo budou také používat patici 479.
Tolik ve stručnosti, a teď nějaké podrobnosti. První je ta, že Merom bude ochotně spolupracovat i se stávající sadou Centrino Napa. Čipsety řady 945 ho totiž podporují, setkáme se jen s určitými omezeními jako jsou pouze 667 MHz FSB a L2 na úrovni stávajících Yonahů.
Paralelizace a MicroOP‘s
Základním předpokladem výkonu dnešních procesorů je takzvaná paralelizace. Poměrně složité příkazy sad x86 jsou rozděleny na řadu velmi jednoduchých instrukcí, tzv. MicroOP‘s. Ty je možno počítat poměrně jednoduše, což zjednodušuje návrh podoby pipelines a umožňuje dosáhnout vyšších frekvencí. Na druhé straně vyžaduje implementaci dekodérů. A právě práce s MicroOP’s je místem, kde se dnes dějí velké věci. Ve Front-Endu, tedy vstupní části procesoru spolupracující s L1 pamětí, jsou řazeny dekodéry. První inovací je šířka hrdla instrukční L1, které činí už minimálně 160 bitů (u Pentií M jen 128 bitů). Dále následují dekodéry instrukcí, Core architektura má tři jednoduché a jeden komplexní (který zvládne až 4 MicroOP's) – celkem tak může za jeden hodinový takt do bufferu doputovat až sedm MicroOP’s, navíc jednoduché dekodéry zvládají širší portfolio instrukcí včetně SSE1 až SSE3 (které dříve uměla jen jednotka komplexní) a navíc i SSE4.
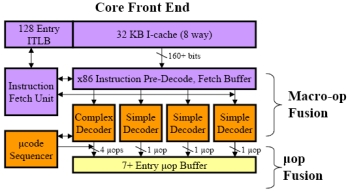
Schéma vstupní části procesoru – vytváření příkazů ke zpracování.
MicroOP’s Fusion je technologie, která pochází už z Pentia M. Umí slučovat stejné MicroOP’s do jediné, která projde jednou pipeline a teprve po provedení výpočtu se rozdělí na dva různé zápisy do paměti.
Macro-Fusion je dalším krokem oproti MicroOP’s Fusion, tedy překládá podobné makroinstrukce (např. x86 nebo x87) rovnou na jedinou MicroOP.
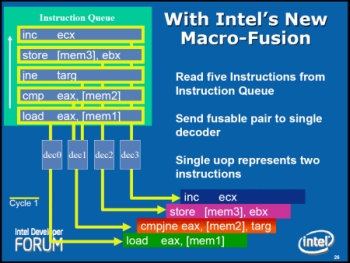
Příklad fungování technologie MacroFusion.
Výpočetní jednotky
Další změnou prošly výpočetní jednotky. Těch procesor obsahuje hned několik –ALU pro operace s celými čísly. Ty jsou konečně plně 64bitové, používají až šestnáct registrů a instrukce AMD64 (x86-64).
FPU jednotky se zaměřují na práci s desetinnou čárkou a MMX instrukční sadou, u Core architektury jsou navíc kombinovány s vektorovou jednotkou pro SSE instrukce, které pomalu MMX vytlačují. Tyto jednotky nově zvládají celé 128bitové operace pro jedinou vektorovou MicroOP’s. Vektorové počítání je potřeba pro takzvané SIMD instrukce (Single Instruction Multiple Data - jedna instrukce, více dat), kam patří například SSE1-4, ale i MMX a 3Dnow! Máme-li pro různé operace společnou proměnnou, můžeme je počítat najednou.
Šíře jedné pipeline je čtyři MicroOP’s za hodinový cyklus a její výpočetní jednotky jsou uspořádány do tři Issue Portů – na každém je ALU jednotka, z toho na 1. komplexní, každý port má i vlastní SSE jednotku, na prvních dvou je pak FPU jednotka s podporou vektorových SSE výpočtů.
Další Issue Porty jsou vyhrazeny pro paměťové operace. Opět jsou tři, jedna pro čtení adres, druhá pro ukládání adres a třetí pro ukládání spočtených dat. Spolupracují s 256ti záznamovým bufferem, který převádí virtuální adresy na fyzické. Oproti Pentiu M je to dvakrát více! Data pak putují do vyrovnávací L1 cache.
Vyrovnávací paměť
L1 cache je rozdělena na datovou a instrukční část, každá má 32 kB. Propojení s paměťovým bufferem i výpočetními jednotkami je 128bitové, což umožňuje načítání kompletních SSE instrukcí. Instrukční část má rozhraní 160bitové kvůli vysokému dekódovacímu výkonu Core architektury.
L2 cache je unifikovaná, takže obsahuje jak data, tak instrukce. Má velikost od 2 MB, během vývoje se počítá s navýšením až k 6 MB u budoucího high-endu. Režim fungování cache pamětí je kombinovaný – L2 může, ale nemusí obsahovat data, která jsou v L1. Oba režimy (tedy buď s duplikovanou L1 pamětí nebo se stálým přepisem) mají své výhody a nevýhody a Intel se z nich snaží vytěžit co nejvíce.
Zásadní problém vícejádrových systémů, sdílení dat mezi jádry, řeší Intel dvěma způsoby –stejně jako u Yonahu je L2 paměť sdílená, takže když jedno jádro dokončí výpočty, může je druhé používat od okamžiku, kdy se dostanou do L2, což je ještě relativně rychlé. Jako novinku přidává sběrnici mezi oběma datovými L1 cache. Bližší informace zatím Intel z pochopitelných důvodů tají.
K L2 a vysoké míře paralelizace výpočtů se váže ještě jeden problém – Memory Aliasing, což je stav, kdy jedna instrukce vyžaduje informaci, kterou některá předcházející instrukce teprve počítá. A v takovém případě se až dosud musely další výpočty zastavit a procesor „běžel“ naprázdno. Technologie Memory Disambiguation odhaduje, kdy k takovému aliasingu nedojde a povolí čtení ještě před zápisem. Mělo by jít o významné zrychlení při načítání dat do pipeline, pokud se ovšem splete, je třeba začít s výpočtem znovu.
Predikace větvení
Predikace větvení podle nějaké podmínky je jednou z nejobtížnějších na určení. Branch Predictor rozhoduje na základě statistiky chování programu, která z větví programu bude pravděpodobněji následovat, a tu pošle k předzpracování. Pokud se netrefí, je třeba znovu výpočet opakovat. Přesnost je kolem 95% a může významně urychlit práci. Ještě obtížnější je odhadovat cykly, resp. podmínky jejich ukončení, každopádně Core architektura obsahuje i loop detector.
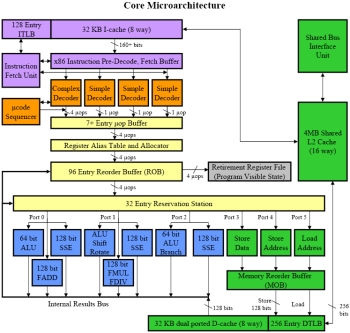
Celkové schéma architektury Intel Core.
Teplotní management
Vedle zvyšování výkonu a optimalizací výpočtů se dnes na procesory kladou ještě docela jiné nároky, u mobilního nasazení zejména. Vzhledem k tomu, že byl použit 65nm proces stejně jako u Yonahu, bylo třeba hledat úspory jinde. Celková spotřeba sice oproti předchozí generaci stoupla, ale jen o 3 W na 34 W, což je vzhledem k výkonu velmi přijatelné. Navíc se celková filosofie změnila, zatímco ostatní procesory se vypínají či zpomalují, Merom má jako základní stav „vypnuto“ a naopak zapíná ty části, které zrovna bude využívat. Došlo to tak daleko, že vypnuté mohou být i jednotlivé datové linky, přeci jen celé 128bitové instrukce se nepoužívají neustále. Implementováno je i digitální měření teploty, které umožní OS, který by tuto featurku podporoval (Windows Vista), velmi snadno vyhodnocovat podmínky práce procesoru, reagovat a vytěžovat jednotlivá jádra.
Shrnutí
Core architektura jádra Merom sice není revoluční, ale přináší tolik nových věcí a zásadních úprav v konstrukci čipu, že pro Intel znamená velký krok, pravděpodobně vpřed. Navazuje na nejlepší tradici Pentií, ale přináší kromě dvou jader i vylepšenou práci s příkazy a instrukcemi, lepší management sdílené vyrovnávací cache paměti, navyšuje počet výpočetních jednotek a ještě výrazně zlepšuje výkon přepočtený na watt. Konkurence bude mít mnoho co dělat, aby stačila této výzvě.
zdroj obrázků: realworldtech.com ; intel.com

















